


1. Asset and allocation management
Asset management is a set of accounting processes that monitor assets whose purchase price exceeds a certain limit, which records information such as purchase price, depreciation, business unit and location. An effective asset management system should provide the basis for establishing a configuration management system.
The management and control objectives of the asset management process focus on managing assets from the perspective of corporate finance rather than IT management. The fixed asset management procedures include specific management procedures for fixed asset procurement plans, purchase applications, installation and commissioning, cost valuation, depreciation provisions, projects under construction to fixed assets, transfer to fixed assets acceptance, custody and maintenance, capitalization of maintenance costs, dismantling and internal allocation, scrapping, idle disposal, external leasing and lending, accounting, etc.
Configuration management is a service management process that identifies and confirms the system's activities such as recording and reporting the status of configuration items and change requests, and verifying the correctness and integrity of configuration items.
Configuration management goes beyond asset management by retaining technical information about configuration items, detailed information about how they relate to each other, and information about the standardization and authorization status of configuration items.
Configuration management also monitors feedback on current information such as the status of IT components, their location, and changes that have been implemented to them. Key points for asset and configuration management include:
(1) Configure the goal of management. Good configuration management can not only reflect the attribute information of a single individual, but also reflect the impact between IT components, and provide sufficient basic information for other processes such as change management, incident management, and problem management.
1) Provide accurate information about IT infrastructure.
2) Monitor and maintain the following information to achieve control over the infrastructure:
All resources required to deliver services;
• Status and history of configuration items (CIs);
• Configuration item relationships.
(2) Fixed asset management related processes. Some key processes to consider and define for fixed asset management are as follows:
-
Asset procurement;
-
asset changes;
-
asset inventory;
-
Assets are leased in and out;
-
Asset scrapping process.
(3) Asset management related documents. Common documents for asset management are defined as follows:
Fixed asset purchase application form;
fixed asset procurement contract;
Signing receipt of fixed assets and equipment;
data center fixed asset ledger;
Inventory of fixed assets;
Idle fixed asset details;
Records of fixed assets going out;
Fixed asset inventory report.
(4) Configure the management database (CMDB). A configuration management database is a database that contains all information related to configuration items and their status and interrelationships. The configuration management database keeps track of all components, their different versions and statuses, and their relationships between components. In its most basic form, a CMDB may consist of some paper forms or a set of checklists.
(5) Factors to be considered in configuration management. The determination of the breadth and depth of configuration management directly determines whether the future management control of configuration management is effective. If the breadth is too broad, it may be difficult to manage and control all key and non-critical assets in it. For configuration management depth, if the definition is too detailed, such as a device configuration item defined to the NIC level, the future management cost will also be extremely high. The selection of configuration management tools, such as automatic discovery, can effectively help you launch configuration management tools. At the same time, in the implementation of change management, the changes in configuration items are included to ensure that the configuration is confirmed and updated before the change is completed, which will also effectively help the effective implementation of configuration management. Here are some common configuration management considerations:
-
breadth of configuration management;
-
depth of configuration management;
-
the association between configuration items;
-
Configuration management tool selection;
-
Binding configuration management to change management.
Data center security management is to ensure the information security, technical security and physical security of the data center through the formulation and implementation of the data center security management organization, basic environment security and information technology security.
Key points for data center security management include:
3) Data center information technology security. It includes asset security management, communication security management, network security management, system security management, data security management, software development security and data center permission security
(2) General principles of data center security management. The general principles of data center security management include the following basic contents:
10) If conditions such as manpower and resources permit, the security level of all information assets related to the data center should be stipulated, and protection measures corresponding to the security level should be formulated.
(3) Security organizational structure.
1) Job setting. Functional departments for information security management should be established, and positions of security supervisors and responsible persons in all aspects of security management should be established, and the responsibilities of each person in charge should be defined. Positions such as system administrator, network administrator and security administrator should be established, and the responsibilities of each job should be defined. Establish a data center information security leadership and coordination mechanism with the responsibility of the board of directors and senior management, with the participation of relevant department heads and internal experts. Documents should be formulated to clarify the responsibilities, division of labor and skill requirements of each department and position of the safety management agency.
2) Staffing. A certain number of system administrators, network administrators, and security administrators should be assigned. A full-time safety administrator should be assigned, and the A and B post system should be implemented, and other positions should not be held concurrently. Key affairs positions should be jointly managed by multiple people.
3) Authorization and approval. According to the responsibilities of each department and position, the authorization and approval matters, approval departments and approvers should be clarified; Approval procedures should be established for system changes, important operations, physical access, and system access, and the approval process should be carried out in accordance with the approval procedures, and a step-by-step approval system should be established for important activities. Regularly review and approve matters, and update information such as projects, approval departments, and approvers that need to be authorized and approved in a timely manner; The approval process should be documented and the approval documents should be saved; Users should be granted the minimum permissions necessary to complete their tasks, and employees in important positions should form a mutually restrictive relationship. Changes in authority should be subject to relevant approval processes and complete change records. A list of system users and permissions should be established, employee permissions should be checked and checked regularly, and the reasons for overstepping users should be identified and adjusted in time, and expired user permissions should be cleaned up and records should be archived.
4) Communication and cooperation. Cooperation and communication between various managers, internal organizations of the organization, and information security functional departments should be strengthened, and coordination meetings should be held regularly or irregularly to jointly deal with information security issues. Strengthen cooperation and communication with ISP companies such as brother companies, the National Information Security Center, public security organs, telecommunications and networking, and emergency coordination mechanisms to effectively handle network and information security incidents. Strengthen cooperation and communication with suppliers, industry experts, professional security companies and security organizations to enhance daily safety protection, emergency handling and fault handling. A contact list of outreach companies should be established, including the name of the outreach company, cooperation content, contact person, contact information, and other information. should pay attention to and participate in information security seminars in the industry, learn and update security knowledge and concepts; Information security experts should be hired as perennial security consultants to guide information security construction and participate in security planning and security reviews.
5) Audit and inspection. The security administrator shall be responsible for conducting regular security inspections, including the daily operation of the system, system vulnerabilities, and data backup. Comprehensive security inspections should be conducted regularly by internal personnel or audit companies, and comprehensive security inspections of data centers should be carried out at least once a year, including the effectiveness of existing security technical measures, the consistency of security configuration and security policies, and the implementation of security management systems. The internal audit department shall conduct an audit of the data center at least once every two years, including the completeness of the relevant management system and the effectiveness of its implementation, the rationality and compliance of relevant operating procedures, the completeness and effectiveness of the information security assurance system, the security of information security risk management, planning and implementation, the operation of information systems, the security of important customer information and data, the effectiveness of emergency management and outsourcing management, the implementation of SLAs, and other important information security guarantees. Assess and manage the security of third-party companies or outsourced projects.
The goal of incident management is to restore normal service operations as quickly as possible in the event of an incident, avoid business disruption, minimize negative business impact, and ensure that the quality of service and availability meet the normal service levels defined in the Service-Level Agreement (SLA). To achieve this, incident management processes must optimally use resources to support the business, develop and maintain effective incident records, and design and apply a unified incident reporting methodology.
3. Incident management
Incidents are events that may cause service interruption or deterioration of service quality and are not standard services. Incidents include not only software and hardware-related errors, but also service requests.
Event management is not about finding the root cause of the system abnormality, but about restoring the system business function as soon as possible, and finding the root cause of the abnormality is the purpose of the problem management process.
The main task of event management is to identify and track events that occur in a timely manner. Triage incidents and provide initial support; Investigate and analyze the incident to identify the potential causes of the incident; resolve incidents and restore service; Track and oversee the resolution of all incidents and communicate at all times. Therefore, the study of incident management is of great significance to solve the service problems existing in IT operation and maintenance, and the timeliness of event management will directly affect the IT service quality and overall operation status of the entire enterprise.
Key points for incident management include:
1. Event records
Incident management records detailed event information, such as when the event occurred, the services affected by the incident, etc. The purpose of this is to facilitate the confirmation of the impact of the incident, and problem management can find the cause of the incident based on this information and closely track the progress of the incident. Automatic generation of basic event records in the event database through system monitoring tools is the ideal solution. The characterization, basic diagnostic data, and information of the relevant configuration items should be included in the event log during the diagnosis and logging phases.
In most cases, incidents are logged by the service desk, and all incidents should be recorded quickly. Avoid repeated recording of the same event. Therefore, when recording an event, a check is required to determine if there are similar records.
2. Incident classification
The purpose of incident classification is to determine the source of the incident so that corresponding actions can be taken to restore normal work to users as quickly as possible, and to minimize or minimize the impact of the incident on IT service quality. In general, many events are recurring, so when an event reappears, it is only necessary to act on the basis of existing experience and measures. When a new incident arises, there is a process to match the problem and well-known bug (knowledge base), and if the match is successful, it can be resolved directly with an existing solution without further investigation, otherwise proceed to the other steps mentioned below.
ITIL usually adopts a three-level classification mechanism for events: classification, subcategory and project. You can classify events based on the failure status of the reported event (assign type to event). Incidents are coded based on their type, status, impact, urgency, priority, SLA, etc., and are provided with recommendations to resolve or address issues, even if they are temporary.
3. Definition of event status
Event status reflects its current state throughout its lifecycle, sometimes referring to its position in the event workflow. Anyone should be aware of the state of each event and what it represents. Typically, examples of event states include: New; received; planned; Assigned/assigned to a professional; Activation status; Suspended; Resolved; Discontinued.
4. Definition of event level
After identifying the categories of incidents, they need to be prioritized to ensure that the support team pays adequate attention to the issue. There are three main factors that determine the level of an incident, namely Impact, Urgency, and Priority. Impact refers to the extent to which an event deviates from normal service levels in terms of the number of users or services affected; Urgency is the acceptable delay for the user or business when resolving a fault; Priority determines the order of handling events and problems according to the degree of impact and urgency, and the priority is usually expressed by a number, priority = urgency × impact.
5. Incident diagnosis and processing
After the identification and recording of the incident, the incident is quickly restored through technical or management means after a preliminary diagnosis. The goal of incident management is first and foremost to resolve issues quickly and restore normal business operations, rather than looking for the root cause of problems. For incidents that have not occurred, if frontline personnel cannot resolve them, the incident escalation should be initiated as soon as possible, with the goal of quickly restoring systems and services. Workaround solutions are often used in the process. If the cause of the incident cannot be found temporarily, the incident needs to be upgraded to problem management, and the root cause of the problem is tracked through problem management until the problem is completely solved and no longer recurs, which belongs to the category of problem management.
6. Event escalation mechanism
If an incident cannot be resolved by a frontline support team within the allotted time, then more experienced personnel and people with higher authority will have to be involved, which is an escalation. It can occur at any time and at any level of support during the incident resolution process. Upgrades are divided into functional upgrades and management upgrades.
(1) Functional upgrade: Personnel with more time, professional skills, or access privileges (technical institutions) are required to participate in the resolution of incidents. This escalation may transcend departmental boundaries and may include external supporters.
(2) Management upgrade: When the authorized current level of the agency is not enough to ensure that the incident can be resolved in a timely and satisfactory manner, a higher-level agency needs to be involved.
7. Event closure
After the incident is resolved and the service is restored, the event reaches the shutdown stage, and the user needs to confirm whether the incident resolution is successful. After the incident is resolved, ensure that all incident information is updated and accurately recorded; At the same time, the classification of the event is adjusted according to the root cause of the incident; For incidents where the root cause is not found, confirm whether they have been transferred to Problem Management. The event can be closed on the basis that the user agrees to the event's solution and the final outcome of the program's execution.
Specific examples of incident management key points are as follows:
1. Classification of data center events
There are many types of events that occur during data center O&M, and we mainly classify data center events based on the type of failure and the event classification method. Events divided from the perspective of faults include: power supply and distribution system incidents, refrigeration system incidents, physical environment events, physical security incidents, monitoring systems, network failures, IT system failures, natural disasters, etc. Combined with the incident rating factors, the event is divided into different levels such as first, second, third and fourth levels. Some enterprises will be divided into three levels, and some enterprises will be divided into five levels. Table 1 is a specific example of event classification. Readers can refer to the following classification examples to define and hierarchically divide event classification according to their own situation. In the classification of actual events, there is no uniform mandatory standard, which is determined by specific business and management requirements. Readers can enumerate examples of specific grading events in their data center based on the rating criteria.
Table 1 Data center event classification examples

Example of a first-level event: Users can define specific event scenarios based on the situation of their data center to facilitate judgment.
(1) Power supply system: The whole power supply system is paralyzed (dual-channel mains power supply interruption, UPS power supply interruption and generator failure to start normally), resulting in power interruption.
(2) Refrigeration system: The service of multiple precision air conditioners was interrupted, causing the temperature and humidity to exceed the SLA commitment threshold.
(3) Physical environment: Large-scale water seepage and water leakage lead to serious safety hazards in the customer's computer room.
(4) Physical security: Terrorist attacks or targeted sabotage that cause customer service interruptions.
(5) Natural disasters: Data centers cannot provide physical indicators to ensure the normal operation of data centers, earthquakes, floods, typhoons, wars, etc.
2. Escalation of data center events
Data center events can be upgraded between different operation and maintenance teams according to different situations, Table 2 is an example of the definition of data center event upgrade, readers can refer to the following upgrade examples, according to their own situation to define and divide the upgrade, in the actual event upgrade, there is no unified mandatory standard, it is determined by specific business and management requirements.
Table 2 Example of a datacenter event escalation definition
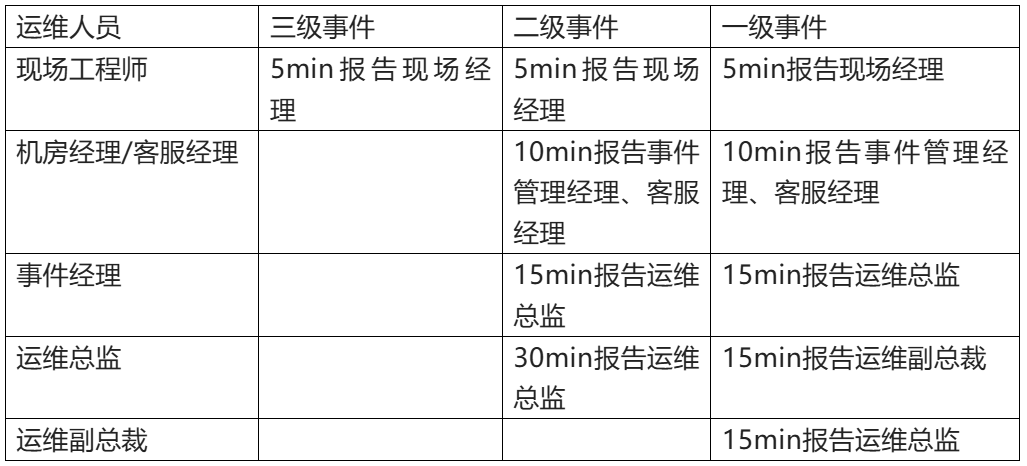
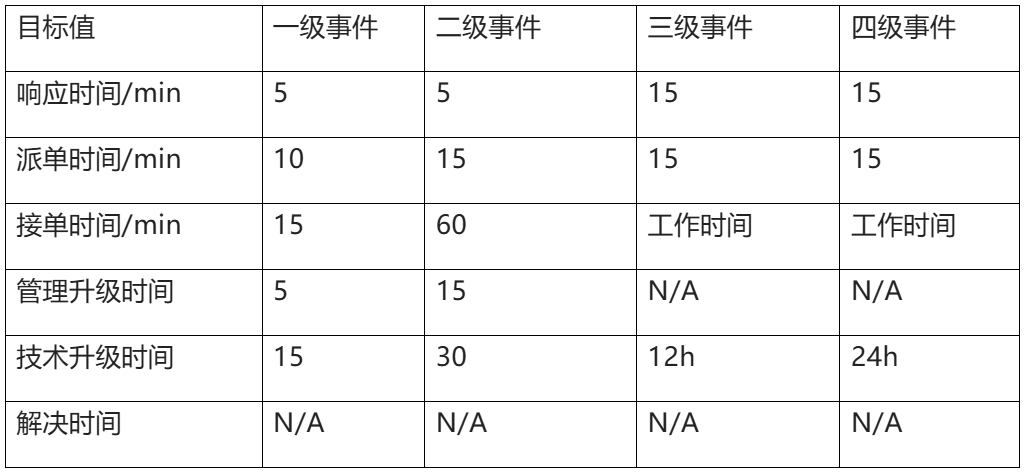
For significant impact events that go beyond the first level, such as events that have a significant impact on the client's business, seriously affect the performance of the contract, and have significant legal and business risks, it is recommended that senior management participate, the participation of public relations media, and the crisis management together with the client.
3. Records of data center events
All kinds of relevant information of data center events should be recorded in a timely manner, generally recorded in the background system, and transmitted in the form of work orders in each processing link. Data center event records include a lot of relevant information, Table 3 is an example of data center event records, readers can refer to the following event record examples to define and divide event record information according to their own situation, in the actual event record, there is no unified mandatory standard, determined by specific business and management requirements.
Table 3 Example of data center event record definition
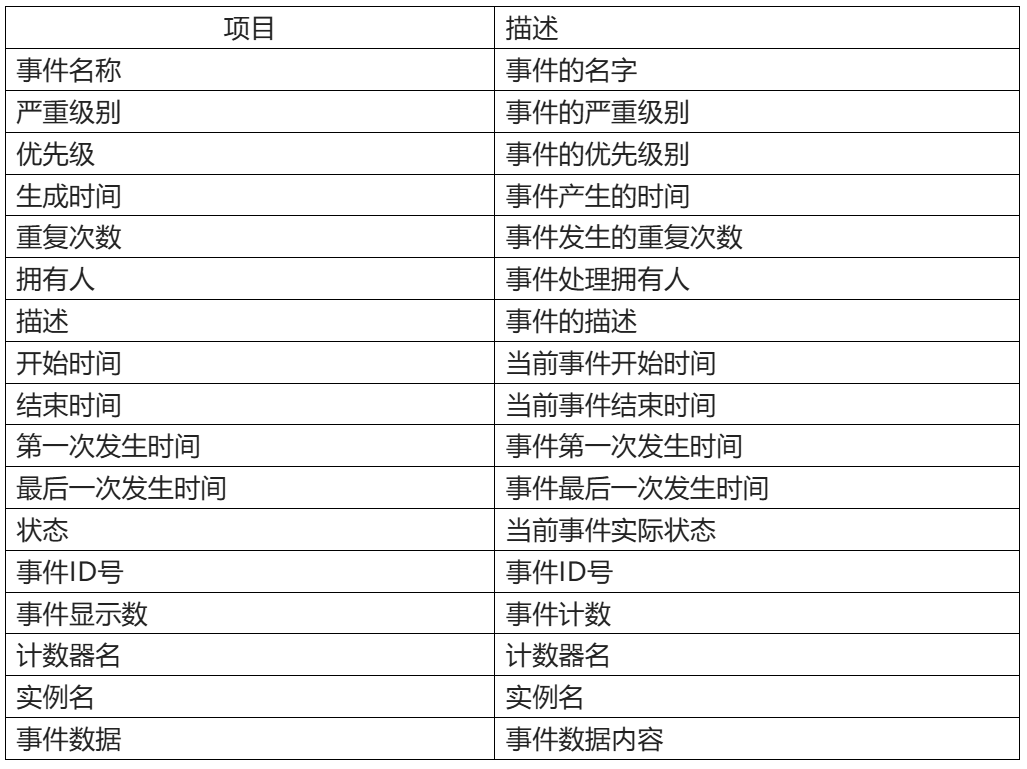
4. Data Center Problem Management
The goal of problem management is to identify the root cause of incidents, minimize the negative impact of incidents and problems caused by IT infrastructure errors, and prevent the recurrence of error-related incidents. Reduce the number of incidents by implementing proactive problem management to identify and resolve issues before they occur.
The problem is the root cause of one or more events that have not yet been diagnosed. Incident management emphasizes restoring to normal service levels as defined in SLAs as quickly as possible with minimal impact on normal business activities for users and the company. Take whatever is possible, including a temporary solution (contingency measure), to resolve the incident quickly, ensuring the best possible quality of service and availability. Unlike incident management, which emphasizes speed, problem management focuses on diagnosing the root cause of an incident and identifying the root cause of the problem, so as to develop appropriate solutions to fundamentally solve the problem and prevent similar incidents from happening again. Incident management often employs ad hoc solutions to restore service as quickly as possible, and problem management takes longer than incident management.
Key points for problem management include:
(1) Identification and recording of problems. In principle, any event caused by unknown causes is related to a certain problem. Identification of problems typically occurs when there are no issues or known errors in the incident management process to match incidents; Through analysis, it is found that the incident has occurred again, or a major event has occurred; Events do not match existing issues or known bugs; Identify the issues leading up to the incident through analysis of the IT infrastructure.
Problem logs, like event logs, are recorded in the Configuration Management Database (CMDB), and problem logs are associated with all associated event logs. The resolution of the incident, as well as the details of the interim solution, should be documented in the issue log and not in the incident log so that they can be used in future associated incidents.
(2) Diagnosis and treatment of problems. After you successfully get the root cause of the problem and find a solution through problem diagnosis, the problem turns into a known error. Problem investigation has a similar process except that it differs from the objectives of an incident investigation. The main purpose of incident investigation is to restore the normal functioning of services, while problem management is to identify the root cause of the problem.
Any contingency measures employed during an incident investigation should be considered during the issue investigation phase and, if necessary, updated with information related to known bugs, solutions, and contingencies in the problem log.
Once a fault in a configuration item is diagnosed, the problem status is changed to a known error, and error control begins. When an issue is diagnosed as a program bug rather than a configuration item failure, the logging should be updated to the correct code and then the issue is closed, usually such a problem does not translate into a known bug.
(3) Closure of the problem. After the conditions specified in the issue closure rule are met, the issue is closed, and all associated events can be closed together.
Specific examples of problem management key points are as follows:
3) From a management perspective, it can be further subdivided. For example, personnel problems can be subdivided into personnel execution problems, personnel skills problems, personnel sense of responsibility and unclear responsibilities.
The core of problem management is to deeply analyze the problem in multiple dimensions and perspectives, find out the "shortcomings" in management and architecture, and solve it fundamentally, so that problem management can really play a role in IT management or data center management. In data center management, problem management is usually ignored because it directly affects the availability of services as much as incident management and change management, so that the remaining problems are not solved in time, and it will also lead to the recurrence of events, thereby reducing the overall availability of the system and services.
In order to promote problem management more effectively, it is recommended that: first, the form is very important, and the problem can be tracked and reviewed on a monthly or quarterly basis, rather than as a daily process work; Second, the choice of problem manager is very important, usually the problem manager is a manager with rich experience and administrative level, in order to schedule resources and have a sense of urgency to solve the problem. If you are a process manager and a part-time problem manager, the difficulty and resistance to the implementation of problem management will be very high.
5. Data Center Change Management (ChangeManagement)
Change management in a data center is a service management process that controls any aspect of the infrastructure to complete changes in the shortest possible outage. The changes referred to here refer to the various changes made to the system or service during the maintenance process. Includes additions, removals, and other modifications.
The purpose of change management is to ensure that all changes are assessed, approved, implemented, and reviewed in a controlled manner, and that standard methods and processes are available. Prevent unauthorized changes from occurring so that the risk of change can be minimized, while minimizing the impact of change-related incidents and ensuring that all changes must be traceable and traceable.
Key points for change management include:
A change request is a formal request to implement a change to one or more specific devices or systems, describing the content of the change and the configuration items associated with the change. A change request is simply a mechanism to request changes to the infrastructure, and it must include the necessary information for the change to be reviewed, approved, and created. Since not every modification request is treated like a change, changes can be divided into two types: standard changes and non-standard changes.
A change request includes:
(2) Change the advisory committee. The change committee should fully assess the impact of the change from both business and technical perspectives. Its membership is flexible depending on the change request and can include anyone who can ensure that the change is adequately evaluated from a business and technical perspective, which can include: change managers (chairs and permanent members), technical experts/consultants, account managers and user group representatives, developers and vendors.
(3) Change type. Changes are usually classified in two ways: one is based on the type of change, which is similar to event classification to distinguish the type of change; The other is to define the level of change based on the impact of the change to confirm the review matrix of the change. Such as major changes, major changes, general changes and standard changes. According to the urgency of the change, it is divided into planned change and emergency change.
(4) Change approval. Different changes have different approval processes and review matrices. For significant changes, a CAB is required to review them. In addition to technical risk assessment, it also involves financial and business assessments. For larger changes, it can be reviewed and determined by the change manager and the head of the relevant department. For general changes or standard changes, it can be filed according to the relevant predefined procedures. The grading and authorization of changes is very relevant to whether the change can be executed well in the enterprise. If too many changes require a complex approval process, high management costs, and low process efficiency, it will also make the change initiator reluctant to go through the change process, resulting in the change risk cannot be effectively controlled.
3) Business approval. Ensure that business managers agree to the proposed changes and that the impact of the changes on the business is satisfactory to them.
(1) Classification of data center changes. According to the level of change risk, the typical change level of data center is divided into four levels: major change, major change, general change and standard change. See the table below for the change of grading method. Users can divide the classification of changes according to their own situation, and in the actual change classification, there is no unified mandatory standard, but is determined by specific business and management requirements.
Data Center Change Rating Table

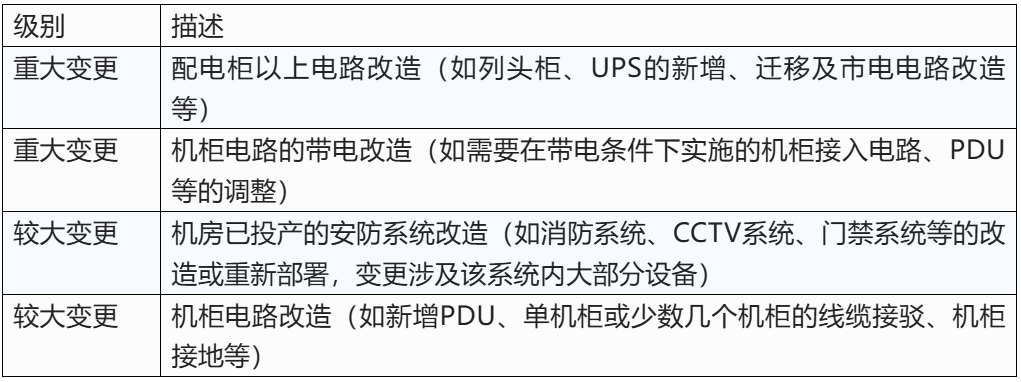
(2) Classification of data center changes. According to the characteristics of the infrastructure to be changed, data center changes can be divided into physical environment changes, infrastructure changes, IT equipment changes, construction changes, IT system changes, network line changes, and asset changes. In order to minimize the time to interrupt business or service in the implementation, it is necessary to approve the change request, determine the priority of the change, and then carry out the change operation. Different categories of changes are graded with reference to the change grading criteria. Readers can divide the classification according to their own situation, and in the actual classification of change, there is no unified mandatory standard, but is determined by specific business and management requirements.



