



The data center network connects the general computing, storage, and high-performance computing resources within the data center, and all data interactions between servers are forwarded through the network. Currently, IT architecture, computing, and storage technologies are undergoing major changes, driving the evolution of data center networks from independent deployment of multiple networks to full Ethernet. Traditional Ethernet cannot meet the business needs of storage and high-performance computing. The hyper-converged data center network uses fully lossless Ethernet to build a new type of data center network, so that the three major types of services of general computing, storage, and high-performance computing can be integrated and deployed on a single Ethernet, and the whole life cycle automation and network-wide intelligent operation and maintenance can be realized.
Why is a hyperconverged data center network created?
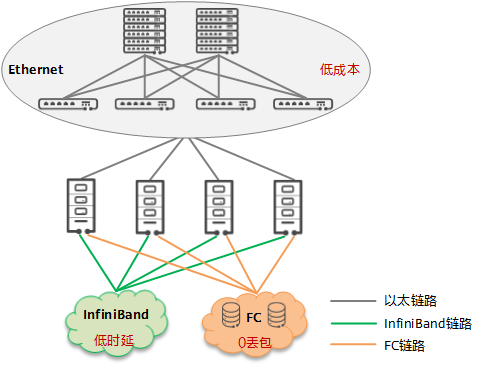
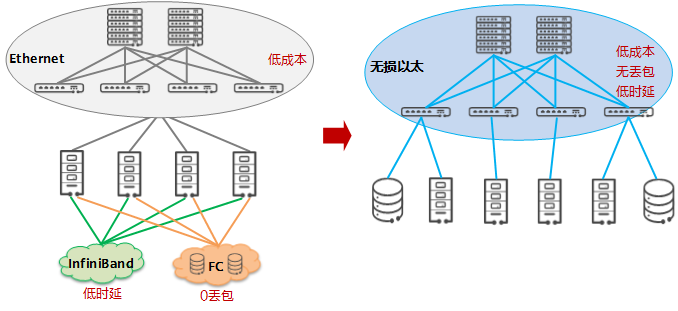
Status: There are three networks in the data center
There are three typical types of services within a data center: general computing (general business), high-performance computing (HPC) business, and storage business. Each type of service has different requirements for the network, such as: the communication between multi-node processes of HPC services has very high latency requirements; The storage service has a very high demand for reliability, requiring 0 packet loss on the network. General computing services are large in scale and highly scalable, requiring low-cost and easy network expansion.
Due to the different network requirements of the above services, three different networks are generally deployed in the current data center:
- The IB (InfiniBand) network carries HPC services
- The FC (Fiber Channel) network carries the storage network
- Ethernet carries general computing services
Changes in the AI era 1: Storage and computing power have increased significantly, and the network has become a bottleneck
A large amount of data will be generated in the process of enterprise digitalization, and this data is becoming the core asset of the enterprise. Mining value from massive data through AI technology has become an unchanging theme in the AI era. Using AI machine learning to assist real-time decision-making has become one of the core tasks of business operations. Compared with the cloud computing era, the mission of enterprise data centers in the AI era is changing from focusing on rapid business deployment to focusing on efficient data processing.
To improve the efficiency of massive AI data processing, the field of storage and computing is undergoing revolutionary changes:
- The storage media has evolved from mechanical hard disk (HDD) to flash memory disk (SSD) to meet the real-time access requirements of data, and the latency of the storage media has been reduced by more than 100 times.
- In order to meet the demand for efficient data computing, the industry is already using GPUs and even dedicated AI chips, which have increased the ability to process data by more than 100 times.
With the significant improvement of storage media and computing power, in high-performance data center cluster systems, the current network communication latency has become a bottleneck for further improvement of the overall performance of the application, and the proportion of communication latency in the entire end-to-end latency has increased from 10% to more than 60%, that is, more than half of the valuable storage or computing resources are waiting for network communication.
In general, with the evolution of storage media and computing processors, network inefficiencies hinder the performance of computing and storage. Only by reducing the communication time to close to computing and storage can the "shortcomings" in the barrel principle be eliminated and the overall performance of the application can be improved.
Changes in the AI era 2: RDMA has become the general trend to replace TCP/IP, but RDMA's network bearer solution is insufficient
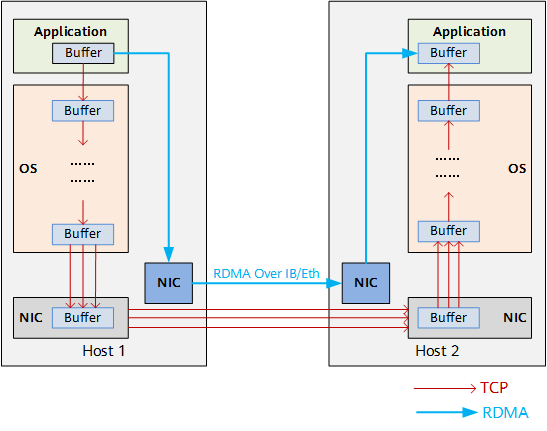
As shown in the figure below, inside the server, the TCP protocol stack generates a fixed latency of tens of microseconds when receiving/sending packets and processing packets internally, which makes TCP protocol stack latency the most obvious bottleneck in microsecond systems such as AI data computing and SSD distributed storage. In addition, as the scale of the network expands and the bandwidth increases, valuable CPU resources are increasingly used to transmit data.
RDMA (Remote Direct Memory Access) allows direct data reading and writing between the application and the NIC to reduce the data transmission latency within the server to nearly 1us. At the same time, RDMA allows the receiver to read data directly from the memory of the sender, greatly reducing the burden on the CPU.
According to the test data of the business, the use of RDMA can increase the efficiency of computing by 6~8 times year-on-year. The transmission delay of 1us in the server also makes it possible to reduce the latency of SSD distributed storage from MS level to US level, so RDMA has become the mainstream default network communication protocol stack in the latest NVMe (Non-Volatile Memory Express) interface protocol. Therefore, RDMA has become the general trend to replace TCP/IP.
In server-to-server internetworking, there are currently two options for hosting RDMA: dedicated InfiniBand networks and traditional IP Ethernet networks, however, both of which have shortcomings:
- InfiniBand network: The architecture is closed, using private protocols, and it is difficult to achieve good compatibility with large-scale IP networks on the existing network. Operation and maintenance are complex, and OPEX remains high.
- Traditional IP Ethernet: For RDMA, a packet loss rate greater than 10-3 will lead to a sharp drop in effective network throughput, and a 2% packet loss will reduce the throughput rate of RDMA to 0. To ensure that RDMA throughput is not affected, the packet loss rate must be less than 1/100,000, preferably packet loss. Congestion packet loss is the basic mechanism of traditional IP Ethernet network, which uses PFC and ECN mechanisms to avoid packet loss, but its basic principle is to reduce the speed of the sender by counter-pressure to ensure that packets are not lost, which actually does not achieve the effect of increasing throughput.
Therefore, the efficient operation of RDMA is inseparable from an open Ethernet with zero packet loss and high throughput.
Change 3 in the AI era: Distributed architecture has become a trend, exacerbating network congestion and driving network change
In the digital transformation of enterprises, represented by financial and Internet enterprises, a large number of application systems have been migrated to distributed systems: replacing traditional small computers with massive PC platforms has brought advantages such as low cost, easy scalability, and independent control, but also brought challenges to network interconnection:
- Incast traffic (multi-point-to-point traffic) will cause traffic bursts at the receiver end, which will instantly exceed the interface capacity of the receiver and cause congestion and packet loss.
- Distributed architecture brings a lot of interoperability between servers.
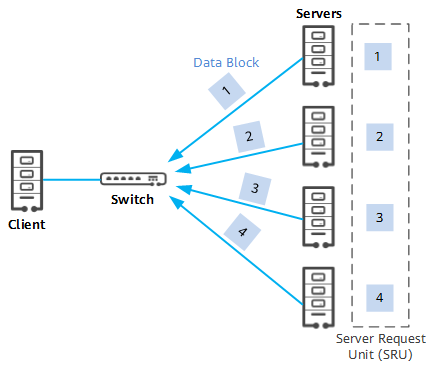
- With the increase in the application complexity of distributed systems, the length of messages interacting between servers is increasing, that is, the traffic has the characteristics of "large packets", which further aggravates network congestion.
What are the core metrics of hyperconverged network data center networks?
From the previous section, in order to meet the demands of efficient data processing in the AI era and meet the challenges of distributed architecture, zero packet loss, low latency, and high throughput have become the three core indicators of next-generation data center networks. These three core indicators influence each other, there is a seesaw effect, and it is very challenging to achieve optimization at the same time.
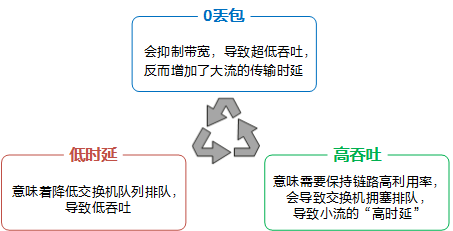
At the same time, it meets 0 packet loss, low latency, and high throughput, and the core technology behind it is the congestion control algorithm. The congestion control algorithm DCQCN (Data Center Quantized Congestion Notification) for a general lossless network requires the cooperation of the network card and the network, and each node needs to configure dozens of parameters, and the parameter combination of the whole network reaches hundreds of thousands. In order to simplify the configuration, only common configurations can be used, resulting in the inability to meet these three core metrics at the same time for different traffic models.
What are the similarities and differences between hyperconverged data center networks and HCI?
HCI (Hyper-Converged Infrastructure) refers to the fact that not only are the resources and technologies such as computing, networking, storage, and server virtualization in the same unit device, but also multiple sets of unit devices can be aggregated through the network to achieve modular seamless scale-out to form a unified resource pool.
HCI consolidates virtualized compute and storage into a single system platform. Simply put, it is to run virtualization software (hypervisor) on a physical server, and run distributed storage services on the virtualization software for virtual machines to use. Distributed storage can run in a virtual machine on top of virtualization software or as a module integrated with virtualization software. Broadly speaking, HCI can integrate compute and storage resources, as well as networking and many other platforms and services. It is widely believed that software-defined distributed storage tiers and virtualized computing are the smallest set of HCI architectures.
Unlike HCI, hyperconverged data center networks focus only on the network level and provide a new network layer solution for computing and storage interconnection. Using hyper-converged data center networks does not require the transformation and convergence of computing and storage resources like HCI, and it is easy to achieve low-cost rapid expansion based on Ethernet.
The hyper-converged data center network is based on open Ethernet, and through unique AI algorithms, the Ethernet network can meet the demands of low cost, 0 packet loss and low latency at the same time. Hyperconverged data center networks have become the best choice for data centers in the AI era to build a unified and converged network architecture.
Hyperconverged data: What is the value of a data center network?
Traditional FC private networks and IB private networks are expensive, have a closed ecosystem, require dedicated personnel for operation and maintenance, and do not support SDN, which cannot meet the demands of cloud-network collaboration and other automated deployments.
Using Huawei's hyperconverged data center network provides the following values:
- To improve end-to-end service performance, Huawei's hyper-converged data center network can reduce computing latency by up to 44.3% in HPC scenarios and increase IOPS by 25% in distributed storage scenarios, and ensure zero packet loss in all scenarios.
- Huawei's hyperconverged data center network can provide 25G/100G/400G networking to meet the demand for massive data bandwidth in the AI era.
- Reducing costs and increasing revenue, the network accounts for only about 10% of data center investment, and has a leverage effect of 10 times compared to server/storage investment (accounting for 85%), which greatly reduces server and storage investment. Huawei's hyper-converged data data center network can bring a 25% improvement in storage performance and a 40% increase in computing efficiency, which will bring dozens of times the ROI (Return On Investment) capability.
- Huawei's hyperconverged data center network supports full-lifecycle service automation with SDN cloud-network collaboration, reducing OPEX by at least 60%. In addition, since Huawei's hyperconverged data center network is essentially Ethernet, traditional Ethernet O&M personnel can manage it and rely on Huawei's intelligent analysis platform iMaster NCE-FabricInsight to perform multi-dimensional and visual network operation and maintenance.
Hyperconverged Data How Does a Data Center Network Work?
As mentioned above, Ethernet is used to carry RDMA traffic, and the current protocol used is RoCE (RDMA over Converged Ethernet) v2. Huawei's hyper-converged data center network uses the iLossless intelligent lossless algorithm to build a lossless Ethernet network, which is a collection of technologies that truly solve the problem of congestion and packet loss in traditional Ethernet networks through the cooperation of the following three technologies, and provide a network environment with "no packet loss, low latency, and high throughput" for RoCEv2 traffic to meet the high-performance requirements of RoCEv2 applications.
- Flow control technology, flow control is end-to-end, what needs to be done is to suppress the transmission rate of the transmitter so that the receiver can receive it in time to prevent packet loss in the case of congestion of the device port. Huawei provides PFC deadlock detection and deadlock prevention to prevent PFC deadlock in advance.
- Congestion control technology is a global process that allows the network to withstand the existing network load, which often requires the synergy of forwarding devices, traffic senders, and traffic receivers, and the congestion feedback mechanism in the network to adjust the traffic of the entire network to alleviate and relieve congestion. In the congestion control process, Huawei provides AI ECN, iQCN, ECN Overlay, and NPCC functions to solve the problems of traditional DCQCN.
- Intelligent Lossless Storage Network Technology: To better serve the storage system, Huawei provides the iNOF (Intelligent Lossless Storage Network) function to quickly control the host.



