


summary
Starting from the development trend of large model technology, the architectural characteristics and computing power requirements of multimodal, long-sequence and hybrid expert models are analyzed. Focusing on the demand of large models for huge computing power scale and complex communication modes, this paper quantitatively analyzes the development problems and technical challenges of the current large model computing power infrastructure from the aspects of computing power utilization efficiency and cluster interconnection technology, and puts forward the development path of high-quality computing power infrastructure with application-oriented, system-centered and efficiency-oriented.
Key words: multimodal model; long sequence model; Hybrid expert model; computing power utilization efficiency; cluster interconnection; High-quality computing power
introduction
In recent years, the rapid development of generative AI technology, especially large language models (LLMs), has marked an unprecedented new era of artificial intelligence. The improvement of model capabilities and the evolution of architecture have given rise to new computing power application paradigms, posing new challenges to the required computing power infrastructure.
1. The development trend of large model technology
1.1 Large language models
The original language model was mainly based on simple statistical methods, but with the advancement of deep learning technology, the model architecture has gradually evolved from Recurrent Neural Network (RNN) to Long Short Term Memory (LSTM) to Transformer, and the complexity and capabilities of the model have been improved one after another. In 2017, Ashish Vaswani et al. first proposed the Transformer architecture, which quickly became the cornerstone of large language model development. In 2018, BERT achieved unprecedented results in a number of natural language processing tasks through pre-training and fine-tuning, which greatly promoted the development and application of downstream tasks. From 2018 to 2020, OpenAI successively released GPT-1, GPT-2, and GPT-3, and the number of parameters of the model increased from 100 million to 100 billion, showing an almost exponential improvement in performance on a number of natural language processing tasks, demonstrating the effect of Scaling Law in practical applications. At the end of 2022, after the release of ChatGPT, it triggered a round of LLM craze, and many companies and research institutions around the world developed hundreds of large language models such as LLaMA, Wenxin Yiyan, and Tongyi Qianwen in a short period of time. Most of the models in this period were based on Transformer infrastructure, trained on large amounts of text data, and able to perform multilingual tasks by learning patterns and relationships in large-scale datasets. However, the development of LLM quickly encountered two significant problems: first, the model's ability is limited to the understanding and generation of text information, and the actual application scenarios are limited; Second, the dense model architecture characteristics will make the improvement of model capabilities inevitably accompanied by an exponential increase in computing power demand, and the speed of model capability evolution is limited in the context of limited computing power resources.
1.2 Multimodal model
In order to further improve the general capabilities of large models, researchers began to explore the application of models in non-text data (such as images, videos, audio, etc.), and then developed multimodal models. This type of model can process and understand multiple types of input data, realizing cross-modal information understanding and generation. For example, OpenAI's GPT-4V model can understand image information, while Google's BERT model has been extended to VideoBERT for understanding video content. The emergence of multimodal models has greatly expanded the perception capabilities and applications of AI, from simple text processing to complex visual and sound processing. Multimodal models use transformers in the same basic model architecture as LLMs, but often need to design specific architectures to handle different types of input data. For example, they may incorporate Convolutional Neural Networks (CNN) components that specialize in processing image data, requiring the use of cross-modal attention mechanisms, joint embedding spaces, or special fusion layers to achieve effective fusion of information from different modalities.
1.3 Long sequence model
Researchers have found that by expanding the context window, large models can better capture global information, help to more accurately preserve the semantics of the original text, reduce the occurrence of hallucinations, and improve the generalization ability of new tasks. Since 2023, mainstream large models have been continuously improving their processing capabilities for long sequences (see Figure 1), for example, GPT-4 Turbo can handle up to 128 K of context, compared with GPT-3.5's 4K processing power has increased by 32 times, Anthropic's Claude2 has the potential to support 200 K contexts, and Moonshot AI's Kimi Chat has increased its Chinese text processing capacity to 2 000 K. From the perspective of model architecture, traditional LLM training mainly performs tensor parallelism on the two core units that take the most time in Transformer, the Multi-Head Attention (MHA) and the Feedforward Neural Network (FNN), but retains the normalization layer and the discard layer. This part of the element does not require a lot of computation, but as the length of the sequence increases, a large amount of activation value memory is generated. Since the non-tensor parallel operations are independent of each other along the sequence dimension, the reduction of the activation value memory can be achieved by segmenting along the sequence dimension. However, the increase in Sequence Parallelism (SP) introduces additional All Gather communication operations. Therefore, the training and inference of long sequences will increase the computational complexity and difficulty, and the computational complexity increases with the length of the sequence n squared O(n2), and the model needs to introduce new parallel hierarchies and ensemble communication operations, which will lead to an increase in the proportion of end-to-end communication time, which will have an impact on the model computing power utilization (Model FLOPS Utilization, MFU).
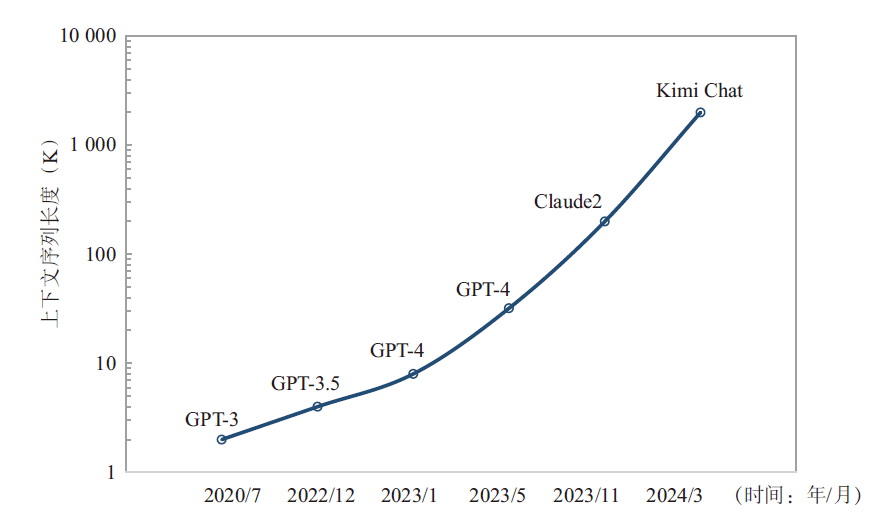
图1 大模型上下文序列长度发展趋势
Fig. 1 Development trend of context sequence length of large models
In order to optimize the computing power overhead while improving the model capabilities, the researchers chose to introduce the conditional computing system, that is, selectively activate some parameters according to the input for training, so that the overall computational overhead slows down with the growth trend of the number of model parameters, which is the core idea of the Mixture of Experts (MoE) model. The MoE model actually builds a sparse model component, decomposing the large network into several "expert" sub-networks, each expert is good at processing a specific type of information or task, and dynamically selects the most suitable experts to participate in the calculation at a given input through a gated network, which can not only reduce the unnecessary computational load, but also improve the professionalism and efficiency of the model. As early as 2022, Google released the Switch Transformer, a MoE model with 160 million parameters, containing 2 048 experts, and under the same FLOPS/Token computational effort, the Switch Transformer model has a 7-fold improvement in training performance compared to the dense T5-Base model.
In this way, the MoE model significantly reduces the need for computing resources compared to dense models of the same size while maintaining model performance, and demonstrates higher efficiency and scalability when processing large-scale data and tasks. Since March 2024, more than 10 MoE models have appeared, including GPT4, Mixtral-8×7B, LLaMA-MoE, Grok-1, Qwen1.5-MoE, and Jamba. However, the introduction of the MoE model layer also brings additional communication overhead, compared with the tensor parallelism, pipeline parallelism and data parallelism commonly used in the LLM training process, the training of the MoE model introduces a new parallelism strategy - Expert Parallelism (EP), which requires an all-to-all communication operation before and after the MoE model layer, which brings higher requirements for hardware interconnection topology and communication bandwidth.
According to the above analysis, multimodal, long-sequence, and MoE models have become a deterministic trend in the evolution of large model architecture, among which multimodal and long-sequence models focus on the improvement of model capabilities, while MoE models take into account the improvement of model capabilities and the optimization of computing power utilization efficiency. This development not only enhances AI's capabilities in content understanding and content generation but also enhances the model's generalization capabilities and task adaptability. However, the evolution of model architecture has also brought about a larger amount of computing power and more complex assembly communication requirements, which has brought greater challenges to the existing computing power infrastructure.
2. Problems and challenges in the development of large model computing power infrastructure
2.1 The scale of available computing power urgently needs to improve the efficiency of computing power utilization
The industry's advanced (State-Of-The-Art, SOTA) model parameter scale and data scale are still growing, and the battle for giants has developed from 100 billion models to trillion models (see Figure 2), and the GPT-4 model has 1.8 trillion parameters, trained on about 13 trillion tokens, and the computing power requirement is about 2.15e25 FLOPS, which is equivalent to running on about 25,000 A100 accelerator cards for 90~100 days. To this end, leading technology companies are accelerating the construction of computing infrastructure, Meta has built two more clusters with about 25,000 H100 accelerator cards on top of the original 16,000 A100 card clusters to accelerate LLaMA3 training; Google has built an A3 artificial intelligence supercomputer with 26,000 H100 accelerator cards, which can provide 26 ExaFLOPS of artificial intelligence performance. Microsoft and OpenAI are building a cluster of 100,000 H100 accelerator cards for GPT-6 training and planning a "Stargate" artificial intelligence supercomputer with millions of cards. It can be seen that Wanka has become a new starting point for advanced large model training in the future.
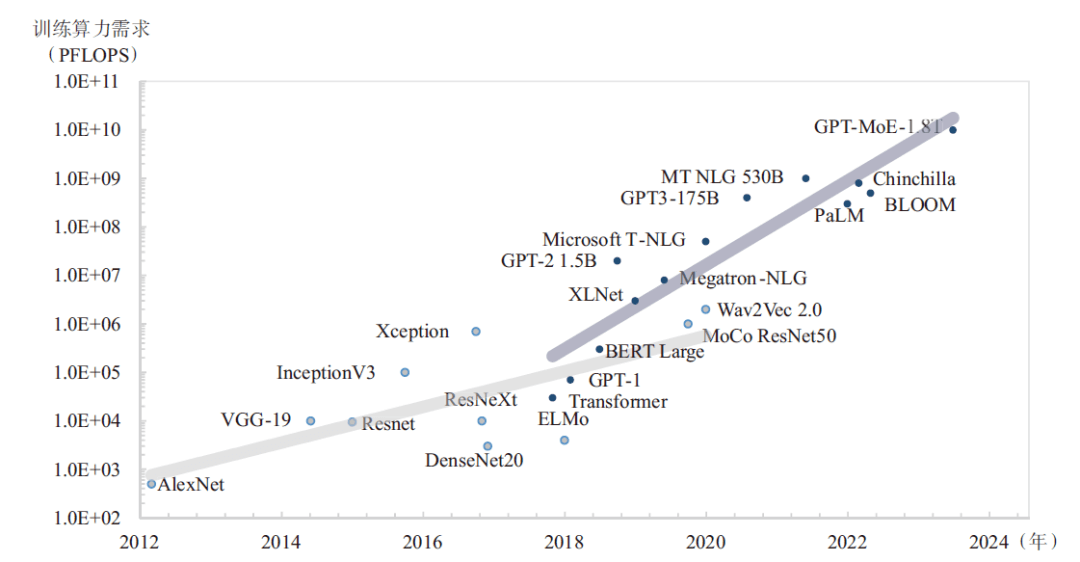
Figure 2 Development trend of large model computing power demand
With the continuous increase in computing power demand and the continuous expansion of computing power scale, the problem of computing power utilization efficiency has become increasingly prominent. According to public reports, the MFU trained by GPT-4 is between 32%~36%, and the root cause is that the bandwidth of the video memory limits the performance of chip computing power, that is, the "memory wall" problem. During the training process of LLM models, model parameters, gradients, intermediate states, and activation values need to be stored in video memory, and parameters and gradient information need to be frequently transmitted to update parameters. High video memory bandwidth can speed up the transmission of parameter and gradient data, thereby improving the efficiency of parameter update and accelerating the speed of model convergence. Therefore, high-end accelerator cards used for AI training will use the most advanced High Bandwidth Memory (HBM) as the video memory to maximize data transmission speed and increase the proportion of computing time, thereby obtaining higher computing power utilization efficiency.
From the perspective of macro technology development trends, the peak computing power of chips has increased by 3 times every 2 years in the past 20 years, but the bandwidth growth rate of memory is only 1.6 times [11]. The performance improvement rate of memory is much lower than the performance improvement rate of the processor, which makes the scissors difference between the computing power and carrying capacity of the chip become larger and larger, and the overall computing power cannot be effectively improved by increasing the number of processors and cores alone. To this end, NVIDIA will have a memory upgrade in the middle of each generation of chips starting from V100, taking the A100 as an example, the first version uses 40 G HBM2 video memory with a bandwidth of up to 1 555 GB/s, and the upgraded version uses 80 G HBM2, with a bandwidth increase of 2 039 GB/s, but this brings limited computing power utilization efficiency and application performance improvement, and the performance of the A100 80 G is only 14% higher in the Bert-Large fine-tuning scenario (see Figure 3).
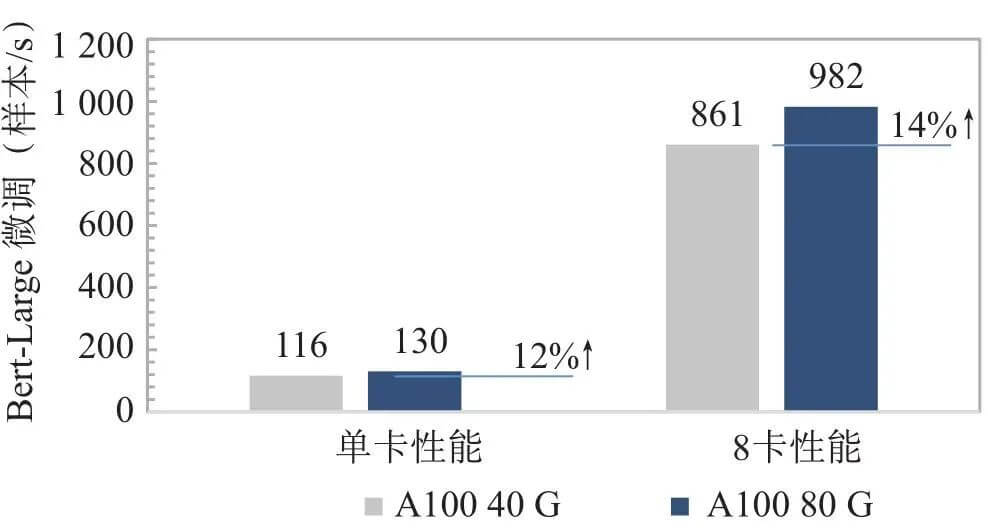
Fig.3 Comparison of the performance of A100 models with different memory bandwidths under the same computing power
In order to quantify the impact of video memory bandwidth on chip computing power utilization efficiency, an artificial intelligence accelerator card with the same video memory (96 G capacity, 2.45 TB/s bandwidth) and different computing power is used to measure the computing power efficiency in the pre-training scenario of LLM models with different parameter scales. As shown in Figure 4(a), in the process of using BF16 computing power accuracy to train the LLaMA-7B model, the utilization rate of BF16 computing power increases significantly with the decrease of chip computing power, and for chips with 443 TFLOPS computing power value, its computing power utilization rate is only 54%, while for chips with 148 TFLOPS computing power, the computing power utilization rate reaches 71.3%, which means that the memory bandwidth limits the computing power utilization efficiency of high-computing power chips. The same pattern is reflected in the pre-training results of models with larger parameter scales, such as LLaMA-13B and GPT-22B. As shown in Fig. 4(b), when the nominal BF16 performance increases from 148 TFLOPS to 298 TFLOPS, that is, when the nominal computing power is increased by 2 times, the available computing power increases by only 1.8 times, or the computing power is lost by 29.6%; When the BF16 performance continues to increase from 298 TFLOPS to 443 TFLOPS, that is, the nominal hashrate increases by 48.8%, the available hashrate performance only increases by 22.4%, and the computing power loss is as high as 42.1%. From this, it can be inferred that the available computing power revenue brought about by further improvement in computing power performance will show a marginal decrease due to the limitation of video memory bandwidth, that is, the MFU trained by GPT-4 is less than 40%. It can be seen that the "memory wall" is the biggest bottleneck that limits the expansion of the current available AI computing power.
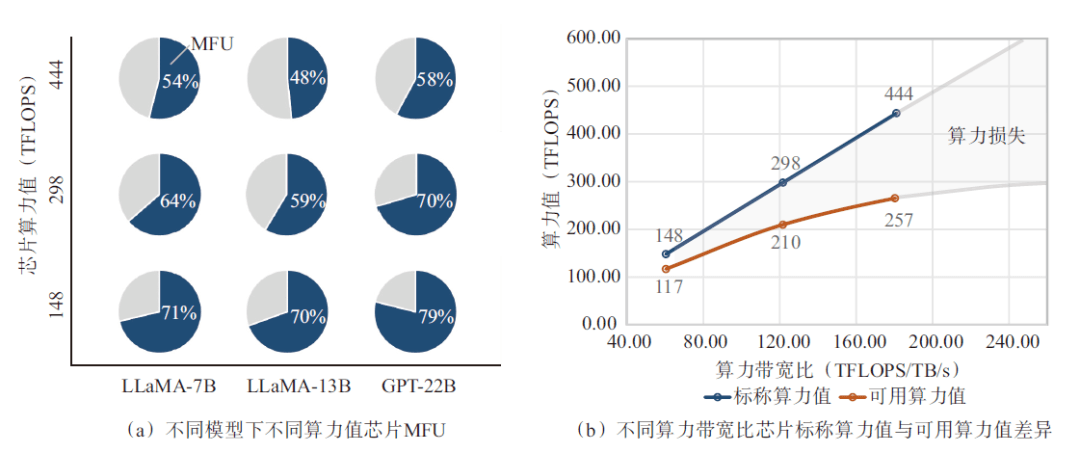
Fig.4 The impact of video memory bandwidth on computing power utilization efficiency
2.2 Cluster performance improvement relies on cross-scale and multi-level interconnection
Driven by the law of scale, the number of parameters of the SOTA model increases at a rate of 410 times every 2 years, and the computing power demand increases at a rate of 750 times every 2 years. Therefore, the construction of multi-core interconnection clusters has become the only way for the development of large model technology, and the scale of SOTA model training clusters has also developed from kilocards to 10,000 cards in a short period of time, and the realization of cluster performance will be affected by multiple factors such as video memory bandwidth, inter-card interconnection bandwidth, inter-node interconnection bandwidth, interconnection topology, network architecture, communication library design, software and algorithms, and the construction of large-scale accelerated computing clusters has evolved into a cross-scale and multi-level complex system engineering problem.
From the application level, large model training often requires an organic combination of multiple distributed strategies to effectively alleviate hardware limitations in the LLM training process. For models based on Transformer architecture, commonly used distributed strategies include data parallelism, tensor parallelism, and pipeline parallelism, each of which has different implementation methods and introduced collection communication operations. Among them, the communication and calculation ratio of data parallel and pipeline parallel is not high, and usually occurs between computing nodes. The core idea of tensor parallelism is to split the two core units in the Transformer Block, the multi-head self-attention layer and the feedforward neural network layer, in which the multi-head self-attention layer is split in parallel according to different heads, while the feedforward neural network layer is split in parallel according to the weights. When using tensor parallelism, each Transformer Block will introduce two additional All Reduce communication operations on forward computation and backpropagation, respectively. Compared with data parallelism, tensor parallelism has a higher communication and computation ratio, which means that tensor parallel algorithms require higher communication bandwidth between computing devices. Therefore, in practical applications, tensor parallelism algorithms are generally limited to a single computing node. As mentioned above, as large models further evolve to multi-modal, long-sequence, and hybrid expert architectures, distributed strategies have also become more complex, and the introduction of sequence parallelism and expert parallelism has also brought more All Gather and All-to-All communication operations, similar to tensor parallelism, which requires ultra-low latency and ultra-high bandwidth communication capabilities between computing devices, thereby further improving the performance requirements for a single computing node or computing domain.
From the hardware level, the design of interconnection needs to meet the needs of efficient expansion of computing power on the one hand, and on the other hand, it must also match the requirements of parallel training set communication for interconnection topology. Interconnection design can be divided into on-chip interconnection, inter-chip interconnection and internode interconnection according to scale. The physical scale of on-chip interconnection is the smallest, the technical difficulty is high, and it is necessary to use chiplet technology to seal multiple chiplets and establish ultra-high-speed interconnection links. Taking NVIDIA's B100 chip as an example, due to approaching the limit of the lithography process, the computing power per unit area of the chip is only increased by 14% compared with the previous generation, and the further improvement of performance can only be achieved by increasing the silicon area, but this is limited by the mask limit. Therefore, on the basis of increasing the single die area as much as possible, NVIDIA integrates the two dies into a package through a more advanced Chip on Wafer on Substrate (CoWoS) process, and interconnects them through 10 TB/s NVLink, so that the two chips can be used as a unified computing device architecture (Compute Unified Device Architecture, CUDA) on the GPU. It can be seen that under the current process limit and mask limit, chip performance can be further improved through advanced packaging and high-speed die-to-die interconnection, but the packaging yield and high cost of this technical route will also greatly limit the production capacity of the latest chips and affect the availability of chips.
Compared with on-chip interconnection, inter-chip interconnection has higher technical maturity and better availability, usually this part of the interconnection occurs within a single node or hypernode, aiming to build an ultra-high-bandwidth, ultra-low-latency computing domain between multiple cards to meet the extremely high communication requirements of tensor parallelism, expert parallelism and serial parallelism. At present, there are NVLink, PCIe, RoCE (RDMA over Converged Ethernet), and many private interconnection solutions. In terms of interconnection rate, NVIDIA's 5th generation NVLink single-link bidirectional bandwidth has been upgraded from 50 GB/s of 4th generation NVLink to 100 GB/s, which means that the B100/B200 interchip interconnection bidirectional bandwidth can reach up to 1 800 GB/s, and AMD's Infinity Fabric can support up to 112 GB/s peer-to-peer (P2P) interconnection bandwidth. From the perspective of interconnection topology, inter-chip interconnection can be divided into two categories: direct connection topology and switching topology, the direct connection topology is more versatile, and the protocol compatibility is higher, such as AMD MI300X, Intel Gaudi, Cambrian MLU series and other open acceleration specification module (OCP Accelerator Module, OAM) form accelerator card can achieve full interconnection of 8 cards through the universal accelerator substrate (Universal Baseboard, UBB) The problem with the direct connection topology is that the inter-chip interconnection evenly distributes the total bandwidth of each card (Input/Output, I/O), resulting in a low P2P interconnection bandwidth between any two cards. At present, only NVIDIA provides NVSwitch-based interconnection solutions among mainstream chip manufacturers, and all GPU scale-up ports are directly connected to NVSwitch to achieve full-bandwidth, all-to-all interconnection form, which is why NVLink bandwidth is much higher than that of direct-connect topology solutions. In the future, with the increase in single-card computing power and the increase in the number of acceleration cards in a single node, it will become a trend to build higher bandwidth and larger-scale GPU interconnection domains based on Switch chips, but how to achieve latency optimization, congestion control, load balancing, and on-network computing for scale-up networks will also become new challenges.
The scale-out interconnection between nodes is mainly to provide sufficient communication bandwidth for pipeline parallel and data parallel in the parameter plane network, usually using Infiniband or RoCE to form a fat-tree non-blocking network architecture, both of which can realize the interconnection of kilocards or even 10,000 cards through multi-layer networking, such as using 64-port switches. Through the three-layer fat-tree non-blocking networking, about 66,000 card clusters can theoretically be built, and about 524,000 card clusters can theoretically be built using 128-port switches. From the node side, the design of scale-out is divided into two types: external network controller and integrated network controller, the external network controller solution is more versatile, and the network controller in the PCIe standard form is usually connected to the same PCIe Switch chip with the accelerator card in a ratio of 1∶1 or 1∶2 to achieve the shortest scale-out path. According to the existing data center network infrastructure design, the type and number of network controllers can be flexibly selected to form a remote direct memory access (RDMA) network solution, which supports Infiniband cards, Ethernet cards, and customized smart network cards. The integrated network controller solution integrates the network controller directly into the accelerator card chip, such as the Intel Gaudi series, Gaudi2 supports 300 Gbit/s Ethernet scale-out link per chip, Gaudi3 doubles the bandwidth to 600 Gbit/s, and the synchronization of computing and network is completed in the chip, without the intervention of the host, which can further reduce the latency. The internode interconnection solution in the data center has been relatively mature, but with the continuous expansion of the scale of GPU cluster construction, the cost and energy consumption of the internode interconnection solution are also increasing, accounting for 15%~20% of the medium-sized cluster. Therefore, it is necessary to face the actual application needs, balance the three elements of performance, cost, and energy consumption, and finally realize the global optimal internode interconnection scheme design. In addition, the clusters with million-card levels that the leading large model companies are planning have exceeded the scalability limit of the existing network architecture, and a single data center cannot provide sufficient power support for cards of this size at the same time. In the future, ultra-large-scale cross-domain lossless computing power networks will be the key to supporting larger-scale model training.
To sum up, with the growth of large model computing power demand, accelerated cluster interconnection technology has evolved into a cross-scale and multi-level complex system engineering problem, involving chip design, advanced packaging, high-speed circuits, interconnection topology, network architecture, transmission technology and other multidisciplinary and engineering fields.
3. High-quality development path of large model computing power infrastructure
With the evolution of SOTA large model training computing power from 1,000 calories to 10,000 calories and even on a larger scale, energy has gradually become the main bottleneck encountered in the development of large models, under the dual limitations of computing power resources and power resources, the arms race of large models in the future will evolve from "computing power battle" to "efficiency battle", optimize the computing power supply structure, and develop high-quality computing power with five characteristics: high computing efficiency, high energy efficiency, sustainability, obtainability and evaluation.
The improvement of computing power efficiency should form a complete technical system around the production, aggregation, scheduling and release of computing power. In the production of computing power, the design imbalance between computing power and video memory bandwidth is often the main factor leading to the loss of computing power efficiency. Therefore, the collaborative design of chip "computing power-video memory" is crucial, and it is necessary to balance the computing power of the chip and the carrying capacity of the video memory with the goal of computing power efficiency to avoid huge computing power losses under the constraints of video memory bandwidth. In the computing power aggregation link, through the "computing power-interconnection" collaborative design and the "computing power-network" collaborative design, the hierarchical interconnection architecture of high and low speed domains is adopted to match the appropriate inter-chip interconnection and internode interconnection bandwidth for the chip, and solve the communication performance bottleneck, which can further improve the MFU of the chip under the actual business model and improve the return on investment at the cluster level. In the computing power scheduling process, software and hardware faults are quickly located through comprehensive monitoring indicators and anomaly detection, and training is quickly resumed through mechanisms such as breakpoint resumption training and fault tolerance, so as to achieve long-term stable training of large models, so as to improve the overall utilization rate of cluster computing power and reduce the overall training cost of large models. In the computing power release process, it is compatible with the mainstream ecosystem, supports the mainstream frameworks, algorithms and computing accuracy of the industry, and can use the latest algorithm innovations in accuracy optimization, video memory optimization and communication optimization to discover the maximum value of limited computing power in the shortest possible time.
The improvement of energy utilization efficiency needs to aim at energy saving, carry out application-oriented, software-hardware collaboration cluster scheme design, and optimize cluster power consumption at the design level by matching the network scheme of actual available computing power scale on the basis of high-efficiency server system hardware. Furthermore, through the application of multi-level advanced liquid cooling technology in components, systems, cabinets, and data centers, combined with the integrated design of power supply, heat dissipation, cooling, and management, energy efficiency improvement at the deployment level is achieved, and finally the global optimal power usage effectiveness (PUE) is obtained.
In addition, large-model computing power infrastructure has become an important driving force to promote the development of core technologies in the information industry, and it is necessary to gather leading technical solutions in the domestic and foreign industrial chains such as core components, special chips, electronic components, basic software, and application software, accelerate the construction of a hierarchical decoupling, diversified openness, and unified standard industrial chain ecology, reduce dependence on a single technology route, avoid chimney-like development, and achieve sustainable computing power evolution and healthy development of the computing power industry through collaborative innovation in the industrial chain. Continue to promote computing power infrastructure, adopt a convergence architecture, realize multi-heterogeneous computing power resource pooling through hardware reconstruction, provide diversified, elastic, scalable and scalable computing power aggregation capabilities, realize intelligent and efficient management of resource pools through software-defined, provide more efficient and convenient computing power scheduling capabilities, lower the threshold for the use of diversified computing power, and achieve universal and inclusive computing power. Finally, it is also necessary to establish application-oriented, efficiency-oriented, comprehensive and scientific high-quality computing power evaluation standards to promote the optimization of computing power supply structure and promote the healthy development of the computing power industry.
Conclusion
Driven by the joint drive of market, capital and policy, large models have rapidly evolved into multi-modal, long-sequence, and hybrid expert forms, with larger parameters and increasingly complex model architectures, resulting in the demand for larger-scale computing power and more complex communication models. However, the development of computing and storage imbalance seriously limits the efficiency of computing power utilization and brings huge losses of computing power resources, and the growth rate of actual available computing power is difficult to meet the needs of application development. As the scale of clusters develops from kilocalories to 10,000 cards, cross-scale and multi-level interconnection technology will become the key to the efficiency of cluster performance expansion in the future. Under the dual limitations of computing power and power resources, the large model arms race is rapidly changing to the battle for efficiency, and it is urgent to build a complete technical system for high computing efficiency around the four major links of computing power production, aggregation, scheduling, and release, and achieve higher energy efficiency from the level of cluster design and data center deployment, and finally form a sustainable, obtainable, and evaluable high-quality computing power.



